
Note: In this post I use the acronym CDM to mean “Canonical Data Model”.
In my role as an integration team lead I come across many problems again and again. One place many discussions land is around canonical models. It’s not just me it seems as the existence of two blog posts (and many more show)
• https://technology.amis.nl/2016/08/08/soa-benefits-of-a-canonical-data-… (Emiel Paasschen)
• https://www.innoq.com/en/blog/thoughts-on-a-canonical-data-model/ (Stefan Tilkov)
These quite old blog posts were bought to my attention as part of a discussion about weather we really need canonical data models. These blogs were represented to me as opposing views but I don’t think they are. Although titled “Why You Should Avoid a Canonical Data Model” I think Stefan’s article argues that CDMs should be built by development teams rather than a central enterprise architect thus respecting the bounded context for each CDM. I think it’s like saying that each source of truth for data is the owner responsible for the CDM which fits in with the vision Emiel describes. It’s similar having the people in charge of the service designing the API.
The problems I am seeing at my organisation (which may be caused by our lack ability to use modern tools and best practice as much as anything else) are the CDM’s are incredibly expensive. They are developed by a central team using clumsy tools requiring skilled developers. It is hard to get data mappings between systems (ever tried to give a business analysist an xsd file as a way of letting them know what data is available?)
On the other hand they are needed as teams struggle with rapid application development tools requiring data from across the enterprise. As the systems they rely on for the data change and evolve they pay a heavy cost caused by the tight coupling and lack of reuse.
Also, both the CDM articles I refer to above miss what for me has been one of the biggest reasons we need to use CDM’s - Supplier de-coupling. Currently 90% of my nightmares seem to be supplier created! There are many people involved in the process between my team and a supplier and many things that can go wrong and cause delays. I want as much decoupling as possible! Suppliers have different levels of maturity in how they look after their API’s but there are a lot of awful ones out there. A CDM is a necessary part of insulating us from changes suppliers make in their API’s removing the need for us to make hundreds of code changes across many systems each time.
Unfortunately, where I work a lot of projects are now skipping the CDM completely as they are a very tempting corner to cut. Project managers love being able to cut weeks of development/delay out of their schedules. Advocating for CDMs is difficult since they address long term high level problems that individual projects are rarely interested in. Also the existence of good practice hurts my argument. Suppliers can have major/minor version control and stable release cycles so my argument for a CDM seems weak. It sucks that when it comes down to this suppliers mostly don’t have a lot of these practices figured out.
At the end of the day having a bad API is not a good enough reason for the business not to choose the best product and in my role I will always have to deal with bad API’s.

There is a glaring mistake in the image above – You get tech cred if you spot it!
What am I trying to achieve with Dockpond 2?
I want CDM’s to be used where appropriate, be owned by the right people and be continuously (and rapidly) evolving.
Commoditise CDM’s
I like to think of an analogy of t-shirts when I think of CDM’s. When t-shirts were expensive you only bought as many t-shirts as you needed. You would always look for ways where you can avoid using t-shirts with workarounds, and you would never use an old t-shirt for a non-designed purpose (like cleaning your car). You also took great care looking after the t-shirts to make sure they always looked good.
Fast forward to the times of automated manufacturing and suddenly the whole t-shirt use picture changes. T-shirts are so cheap and you don’t think twice about buying them, you may even buy more than you need ‘just in case’. You use them for their specified purpose and they are in plentiful supply. They are cheap so changing them often is fine (Cover them in fake blood for Halloween etc.). Finally if you find they are good at doing something they were not designed for (like cleaning you car) you don’t think twice about using them for that.
Commoditisation is a great process that makes you look at things differently. Docker technology has commoditised databases and servers greatly expanding the flexibility and agility of IT. CDM’s are a best practice used to ensure loose coupling between suppliers, systems and teams and I think CDM’s should be commoditised as well.
One way to increase the use of best practice is to make it as easy and friction free as possible. Developers will avoid using CDM’s when they add time, hassle and dependencies to the development process. I want to make CDM’s easy enough so that we would be justifying where not to use them rather than the other way around.
If you are using a hub based model and want a new CDM it would be great if you just defined it and it’s fields and the full API with data storage behind it is available at the click of a button!
For CDM use to really be easy they should be as self-documenting as possible and register themselves with a registry for searchability. (Note: maybe not a central registry – each team should have their own which they control. Something like OER could easily re-introduce inter team friction and slow things down removing the advantages of commoditisation.) It should be easy to have Swagger API’s (maybe confluence pages) auto generated. Finally it is vital that they aren’t made by a central team as this adds cost and delays. Individual development teams need to be empowered to create, manage and share their own CDM’s.
Fast CDM lifecycle to remove the need for all design up front (fit better into Agile projects with changing requirements)
Rather than guess all the features up front it should be possible to define what fields we think are required in the data model and iterate on that. This fits much better with the agile method of running projects since requirements are allowed to naturally evolve throughout the project. We should quickly be able to move from V1 to V2 to VX without a seconds thought and have a clear standard for breaking and non-breaking changes.
The first Dockpond did this through storing the CDM’s in GitHub and leveraging tags for minor versions. Major versions were provided through appending a number to the CDN name. This design proved was successful.
Leverage docker API to split system into many small simple components
Dockpond 1 achieved the goal of commoditising CDM’s, but as all POC’s go there many areas that needed development. It ended up as a bit of a monolith with one container supporting many versions of many CDM’s, and required threading code in order to preform live refreshes.
It would be much simpler to split the system down into individual containers for individual CDM versions and let docker take care of refreshing CDM versions by launching containers. Each container could make use of parameters and configs to host individual minor CDM versions. This would require the API gateweay to the system to be reconfigured as CDM versions are added and retired. This could be achieved with a Dockpond 2 Admin program using API’s to orchestrate launching containers and reconfiguring the gateway.
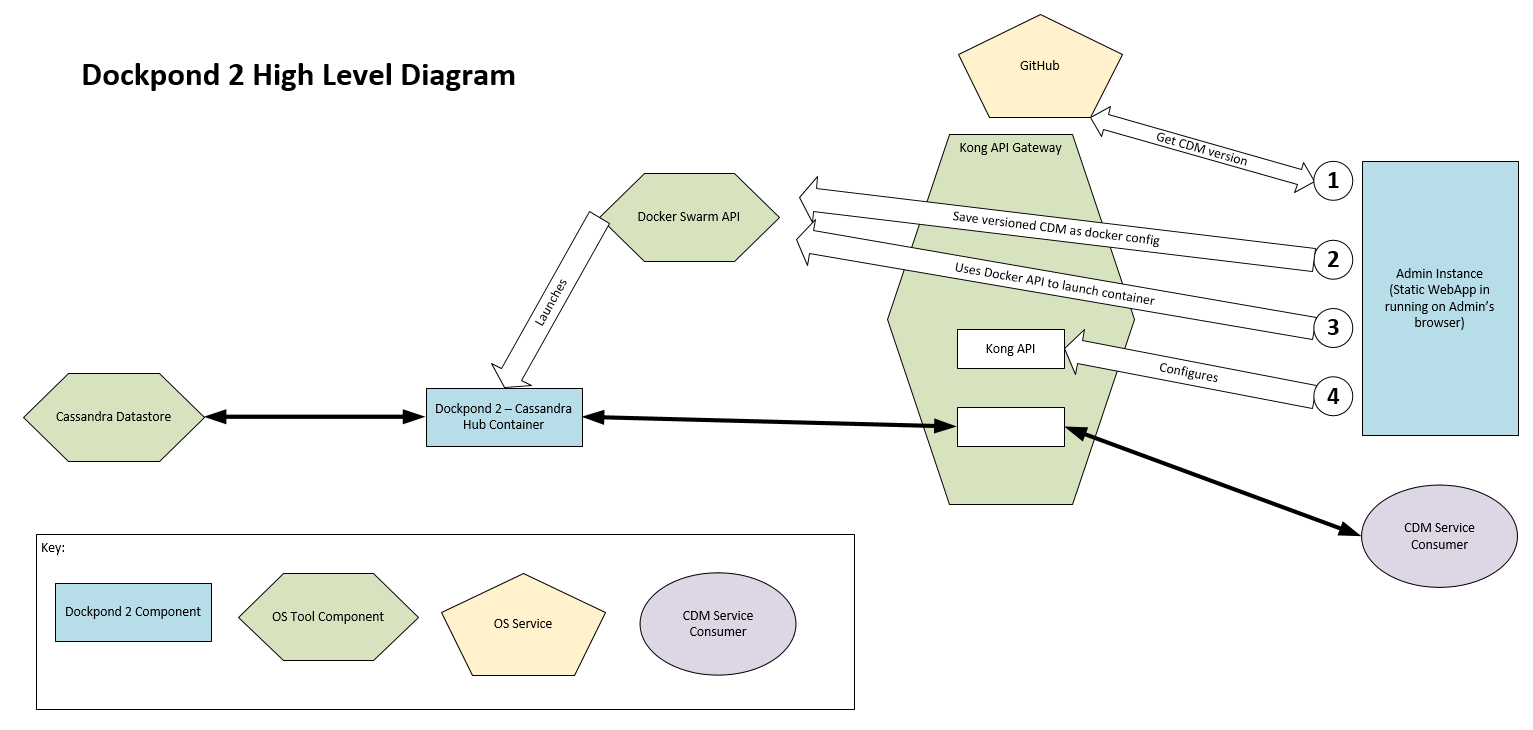
Reduce duplication by developing standard patterns only once
Some integration patterns we use are pub/sub, others are request/response, others need to be hub based. Dockpond 2 could support different container types offering different services around each CDM. E.g. if we want a CDM to be backed by a Cassendra data store we could have a container which provides these services and allow a configuration setting to make the system use that container for services. Other containers could act as proxies to real backend systems.
Scalable using Docker Swarm (and works on AWS, Azure, Etc)
As the system uses Docker containers I am hoping it would be relatively easy to enable it to be scalable. I imagine it would be easy to setup an Azure docker swarm and get it up and running on this.
Conclusion
I hope I have successfully described my basic idea for Dockpond 2. I have my personal website setup using Docker Swarm and Kong and I have been able to securely expose the Kong and Docker API’s which give me a good starting point. My next steps are to think through the idea a little more and look into the design of the admin webapp and hub container.