
This is a follow from My blog post about DynamoDB caching.
As you can see from the metrics implementing application-level caching gave some really good results with my python middleware service:
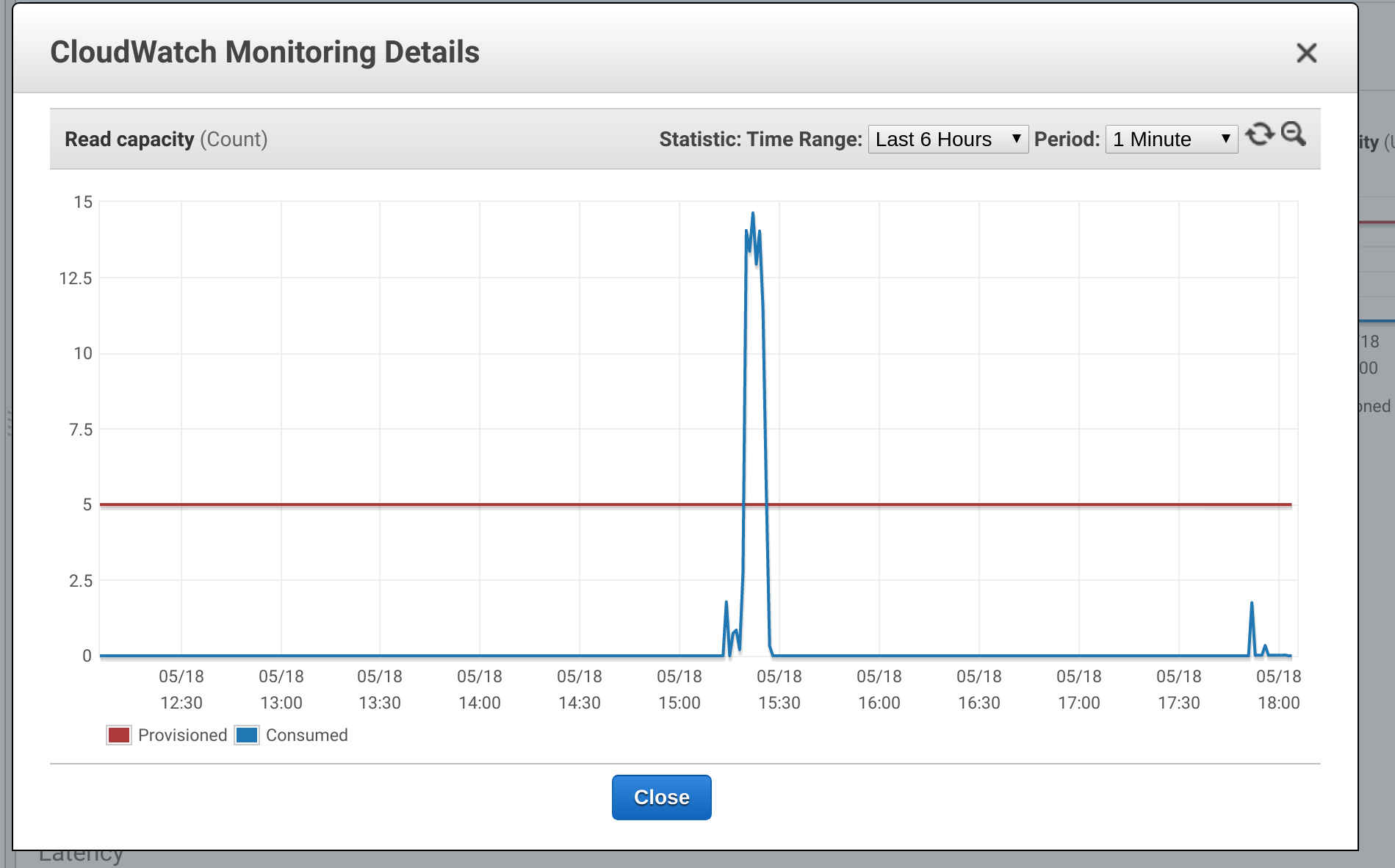
I achieved this by adding a class that received the CRUD calls and checked each read against the cache before sending it on to dynamo DB. It also received the create, update and delete calls and update the cache before forwarding them on. I wanted to make sure there was a cap on the total number of items that are stored in the cache and implementing this proved to be the most interesting part. My first idea was to implement a queue that contained the ID's and times that records were due for removal. This way I could take messages out of the top of the queue as my method for culling the cache. However when I tested this and viewed the metrics I found that the code didn't use the cache at all in my use case.
The issue was that as records were repeatedly read from the cache the same ID was pushed into the queue multiple times. This meant that when an earlier entry was read the item was deleted from the cache despite already having being refreshed. I resolved this by switching the queue to a unique queue and in the process discovered that unique queues are not really a thing in Python so ended up having to implement my own.
I now have a basic caching object store; it doesn't have many configurable options but works in the situation I need it for which is good enough for now.