
Today I updated my saas webapp with it's new webcrawl functionality. Testing it on a small site worked perfectly, and then testing it on a much larger site caused a failure as I went over my DynamoDB provisioned read capacity. I checked out the DynamoDB metrics and this is what I saw for the table.
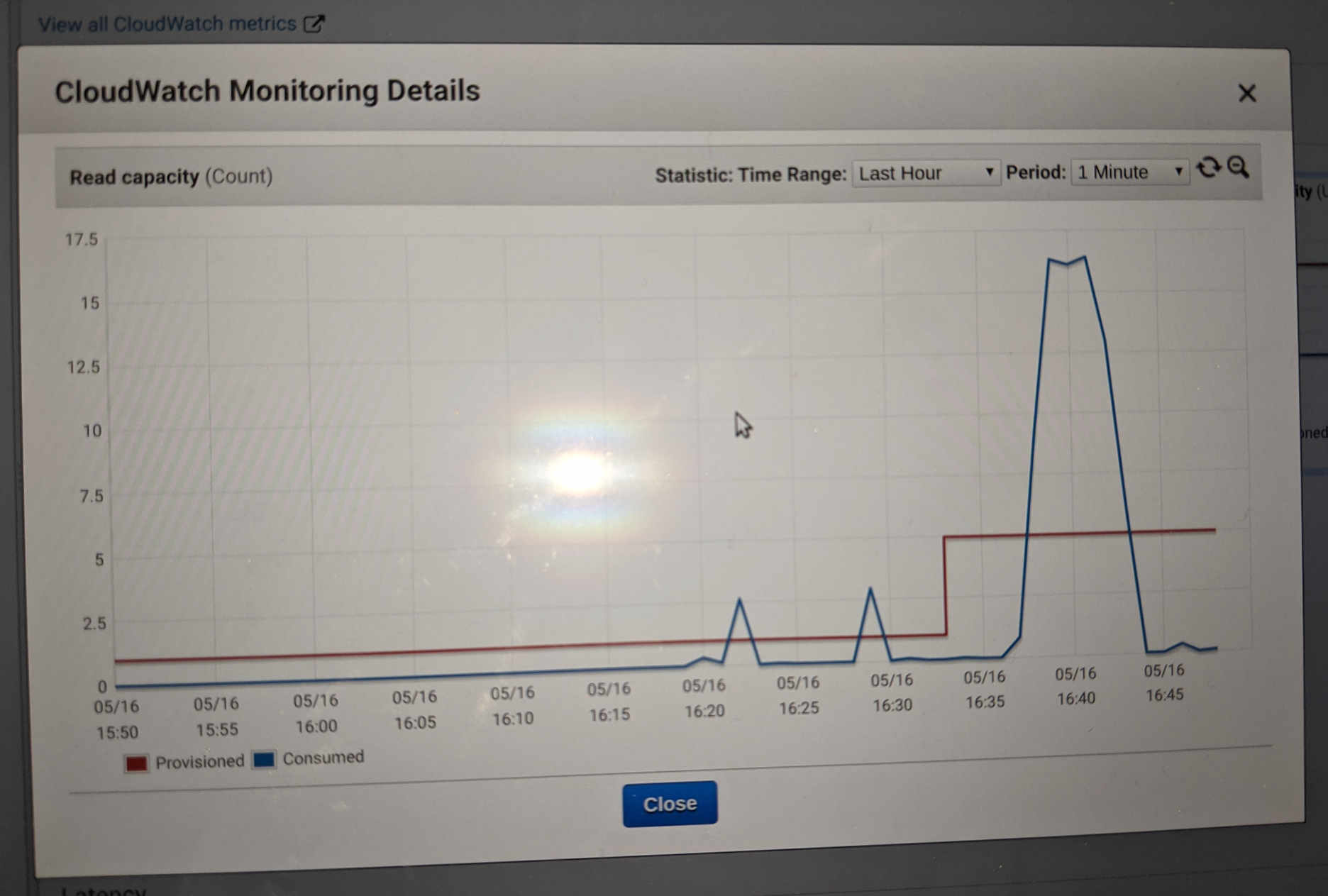
The webcrawl is done by a "webcrawl" microservice running on my infrastructure, and that makes requests to another "graph" microservice responsible for the API's that manipulate the application data. The actual data for the app is not stored in dynamoDB, dynamoDB just stores metadata which needs to be read each time so security credentials and other validations are verified. The problem I am seeing is this is being re-requested every time the request is being raised.
The graph microservice is written in python and uses the boto library to connect to dynamoDB. I have coded this in my "object_store_abstraction" library.
I am now faced with some choices as to how to resolve this:
- Up my provisioned read capacity in DynamoDB
- Setup some kind of caching in front
- Code the app so it makes less requests
Reading around option 1 seems to be a costly option. It may be the wrong decision but I have decided to discount it. As far as option 2 is concerned I am very interested in the possibilities here. I have read multiple blogs and there are many options here. Ones I have thought of so far are:
2.A. Setup Redis in my infrastructure and make boto connect to that
2.B. Do some kind of API caching at my APIGateway
2.C. Use a DynamoDB accelerator paid for service
For option 2.A I wonder if it is a simple config tweak to reconnect boto to Redis. Is it even possible or would I have to recode my app to use a different way of getting data. My current infrastructure doesn't have an APIGateway capable of caching so 2.B is out and I don't have a budget for 2.C.
So that leaves me option 3. (It's a bit of a shame, I am looking forward to learning more about Redis at some point in the future, I guess that's just not today!)
I originally created the "object_store_abstraction" library to decouple my application from the object store I chose during prototyping. I had the aim of moving away from it when I decide I need something more specific to a particular data store. Writing this abstraction didn't feel right initially but as I developed it to supporting more and more datastore types the flexibility it gave me proved very useful. Using it in memory store mode simplified all my tests as I didn't have to rely on mocks and later I found a way I could use it to migrate my app from one data store to another.
Suddenly option 3 becomes a lot easier! I am able to add a 'caching' datastore type which, like the 'migrating' datastore type simply re-uses functionality from any other datastore type and wraps read calls in checks on the cache. In fact, I just have to override the read operations to check the cache. As the object_store library takes it's the configuration from parameters passed via the environment I can configure this from the docker run command. Suddenly I have zero code changes to implement the cache!
So rightly or wrongly I am going to work on option 3, I guess I'll post again and see how it pans out!
Update
I have posted about my experience fixing this.