
While I wait for decision makers where I work to decide on whether to approve our recommendation of looking at a new integration platform I have been able to spend some time getting familiar with the Snaplogic iPaaS. Apart from Snaplogic's own site there isn't too much online discussing it so I thought I would share my first impressions.
The test project – use the SOAP ‘Snap’ to retrieve records from a source system and load these records into a target database. This is interesting because I will have to do some de-pagination. (I think the REST snap has de-pagination it built in but the SOAP one doesn't so I get to implement it myself.) I ended up creating this pipeline twice firstly using a recursive method for subsequent page calls, but then rewriting it completely to try and take advantage of the stream nature of Snaplogic. I ended up with this:
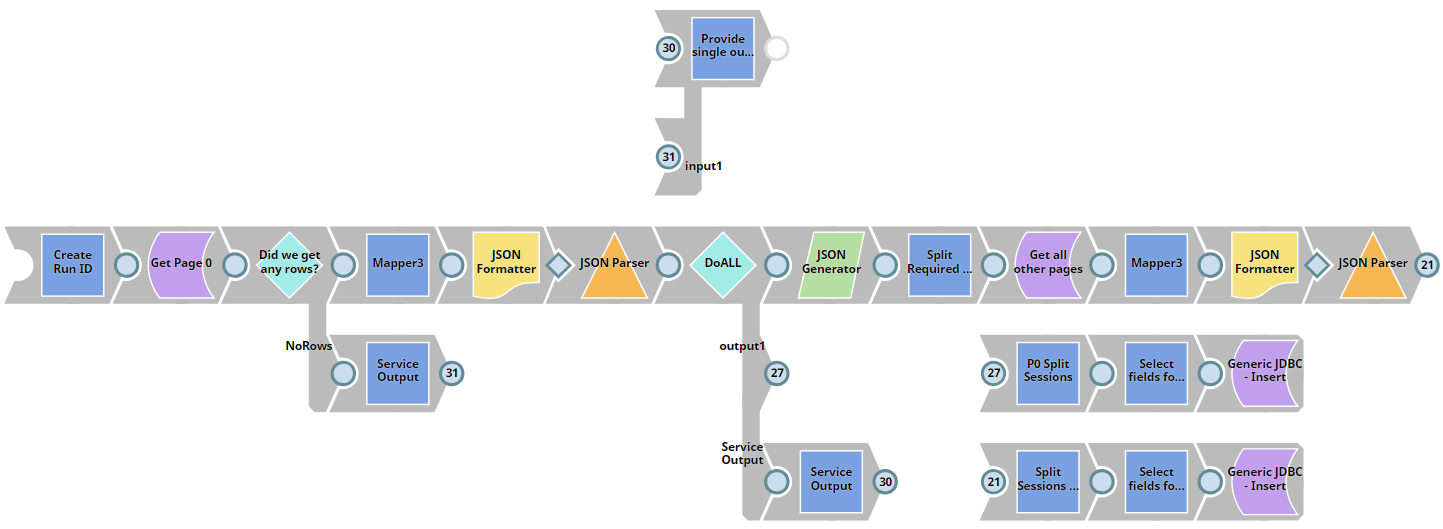
(A nice pretty picture, and it works! Not bad for the forth pipeline I ever created!)
Initial tips given to me by a Snaplogic Tech
- Turn off Auto validation
- In connectors, Grey circle = disconnected, greenish circle = connected - you can click to toggle
- Shift click and drag a square for muti select
Points I learned
Documents
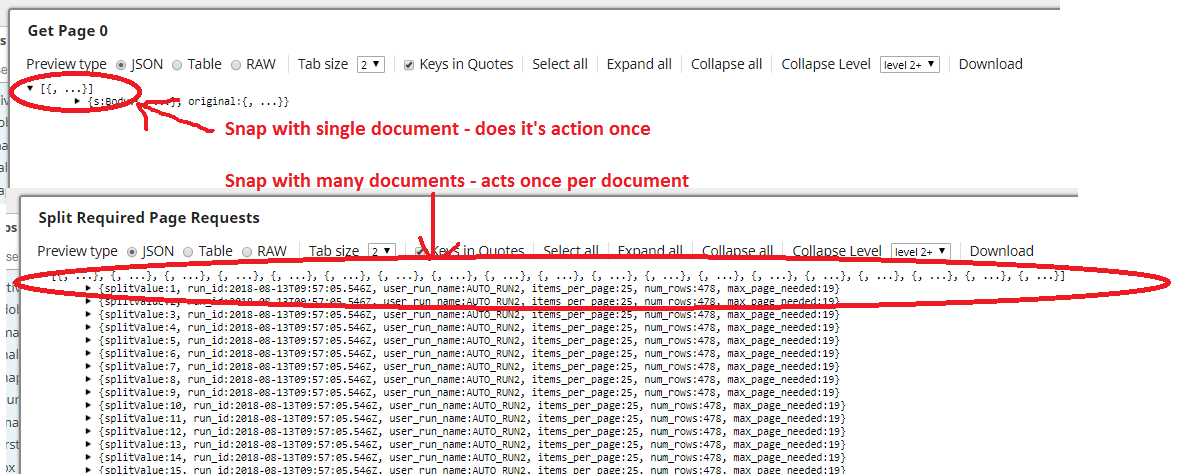
Every Snap preforms a specific action. It will do this action one time per document that passes through it. You can see the documents by clicking on the document icons that appear in the connectors between snaps after you have validated the pipeline.
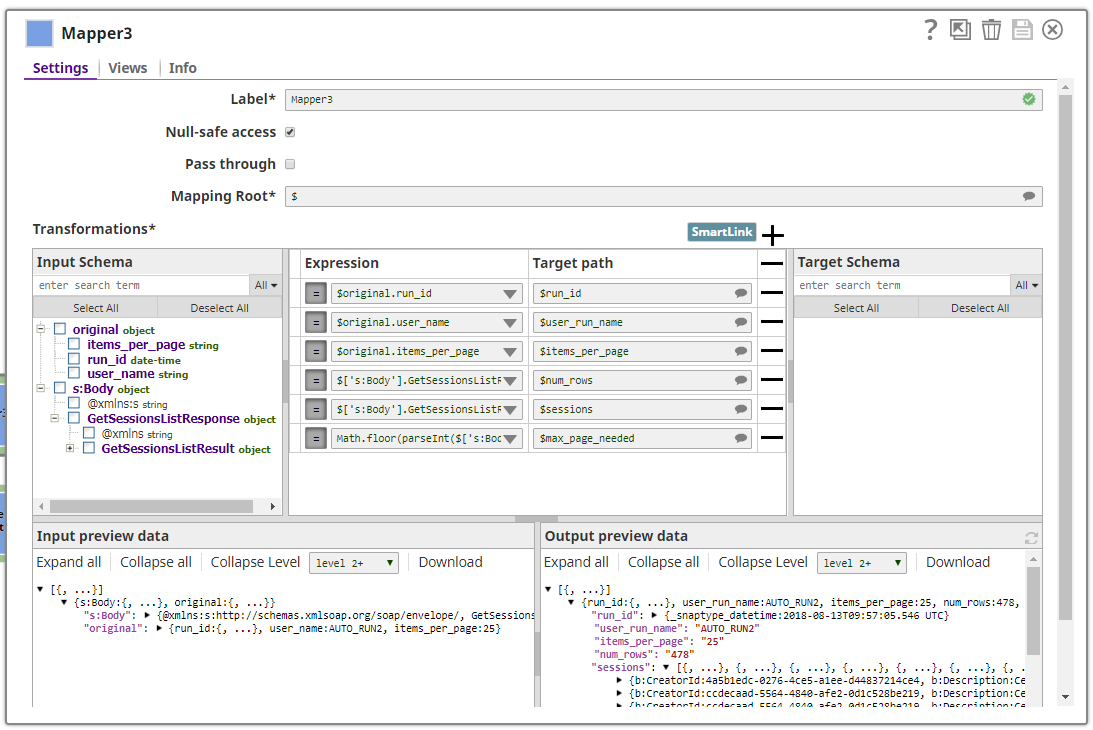
Mapping - Additive and exclusion mapping and pass through
So far my experience with mapping has been good. You can use the Mapper Snaps to map the fields you want or you can check the ‘pass through’ box and use it to remove fields you don’t want. Useful for making shorter mappings. It also works well with complex nested documents and I love the live previews – they really speed me up. I want to learn more about the Input Schema and Target Schema sections through and how Schema’s work more generally with Snaplogic.
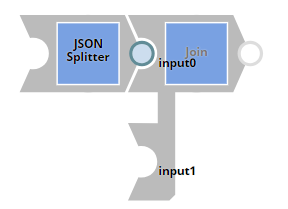
Split is not the opposite of join
In my basic understanding of the English language the words ‘Split’ and ‘Join’ seem to be the inverse operation to me, but this doesn’t seem to be how it is with Snaplogic. The Split snap seems to be a Snap that will take a single document from it’s input stream and split it up into multiple documents in it’s output. Useful if you want get 10 records from a query response and want to insert 10 records into a database. Just take the single response document, put it through the split snap and out will come 10 individual record documents!
So the join must be the opposite right? When I dragged it from the tool pane I got a surprise, a Join must have a minimum of two inputs. It actually looks to me to be more like a database join. There are join types Inner, Left Outer, Outer and Merge. I have only used the outer join in a simple case where I had to combine outputs so my pipeline service only had a unused single output connector. Lots more to learn here with this Snap!
Use JDBC for mysql
The mySQL adapter version didn’t work for my version of mySQL. This was easy to work around, simply use the JDBC adapter and upload the mySQL client library JAR file. Both adapters look the same though so I am unclear what functionality I am missing out of with the mySQL adapter.
JSON generator and Apache velocity
I have been impressed with documentation generally in Snaplogic. Clicking on the question marks generally brings me to useful locations. I was however especially impressed with how the JSON generator and Apache velocity is dealt with. The JSON generator has implemented apache velocity and the velocity user guide is quick to get to. After wasting a few hours causing myself problems because I didn’t properly connect snaps, I was quickly able to start using it. I think this is going to turn out to be a very powerful part of Snaplogic.
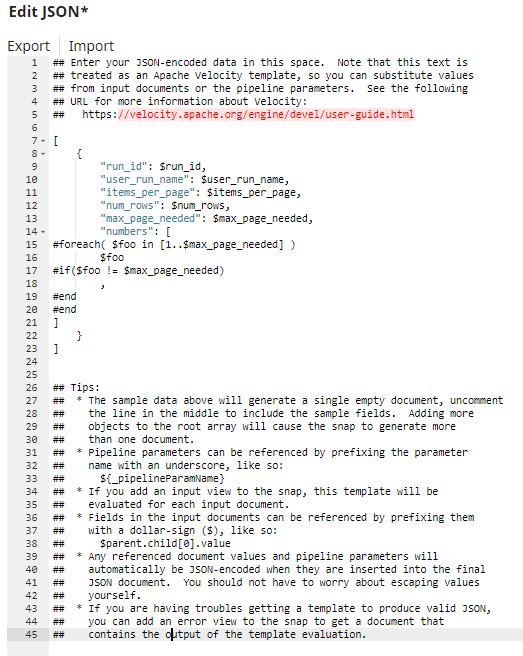
(The example above shows an annoying little extra bit of code I had to put in to get rid of the trailing comma)
Sometimes I need a JSON Formatter than a JSON Parser
Sometimes snaps don't seem to work or display the schema of the messages when they have a SOAP Snap directly upstream. For some reason I need to add a JSON Formatter and a JSON Parser both of which just do pretty much nothing. The snap on the other end then works. By default the formatter comes with a single expression but this can just be deleted and the flow will work.

Sort comings and stuff I still want to work out
- The SOAP Snaps accounts don't support arbitrarily placing the credentials in the SOAP envelope - a requirement for many different SOAP services I must integrate with.
- Moving SOAP Snap between dev/tst/prod and keeping passwords secure
- How would we automate testing?
- How would we automate deployment?
- Need to work out how schemas fit into the picture
- I am not the greatest fan of using it for query integrations - Although this might be what are called 'ultra pipelines' so lots more to learn here!
Summary
I guess my total time in Snaplogic so far is about 8 hours. The fact I have come so far says a lot about the technology, but I am still a newbie and I bet I have a whole heap of misunderstandings. Snaplogic does its job extremely well and I am very enthusiastic about working with it more. Maybe even might look at making myself a Snap - https://developer.snaplogic.com/#developing-snaps!
I don’t know what decision my employer will come up with regarding integration technology but maybe I will end up posting more Snaplogic articles!